
LM Studio is the engine that powers Houtini LM's local processing. This guide walks you through downloading, setting up, and optimising your local AI model for the best performance with Houtini.
Why LM Studio?
Houtini LM needs LM Studio as a prerequisite because it provides the local AI processing power that makes unlimited, private analysis possible. Think of LM Studio as your local AI server - it runs the models that handle all the heavy lifting whilst keeping your code and data completely private on your machine.
What you'll achieve
After completing this setup, you'll have a powerful local AI that can analyse code, generate documentation, and create tests - all without sending your data to external servers or burning through API credits.
Step 1: Download and Install LM Studio
Download LM Studio
Head to the official LM Studio website and download the latest version for your operating system. The installer will guide you through the setup process.
Download LM StudioLaunch LM Studio
Once installed, open LM Studio. You'll be greeted with a clean interface that's designed to make running local AI models straightforward. The main tabs you'll use are "Discover" (for downloading models) and "Developer" (for monitoring Houtini's requests).
Step 2: Download an AI Model
Navigate to the Discover tab
In LM Studio, click on the "Discover" tab. This is where you'll find and download AI models that can run locally on your computer.
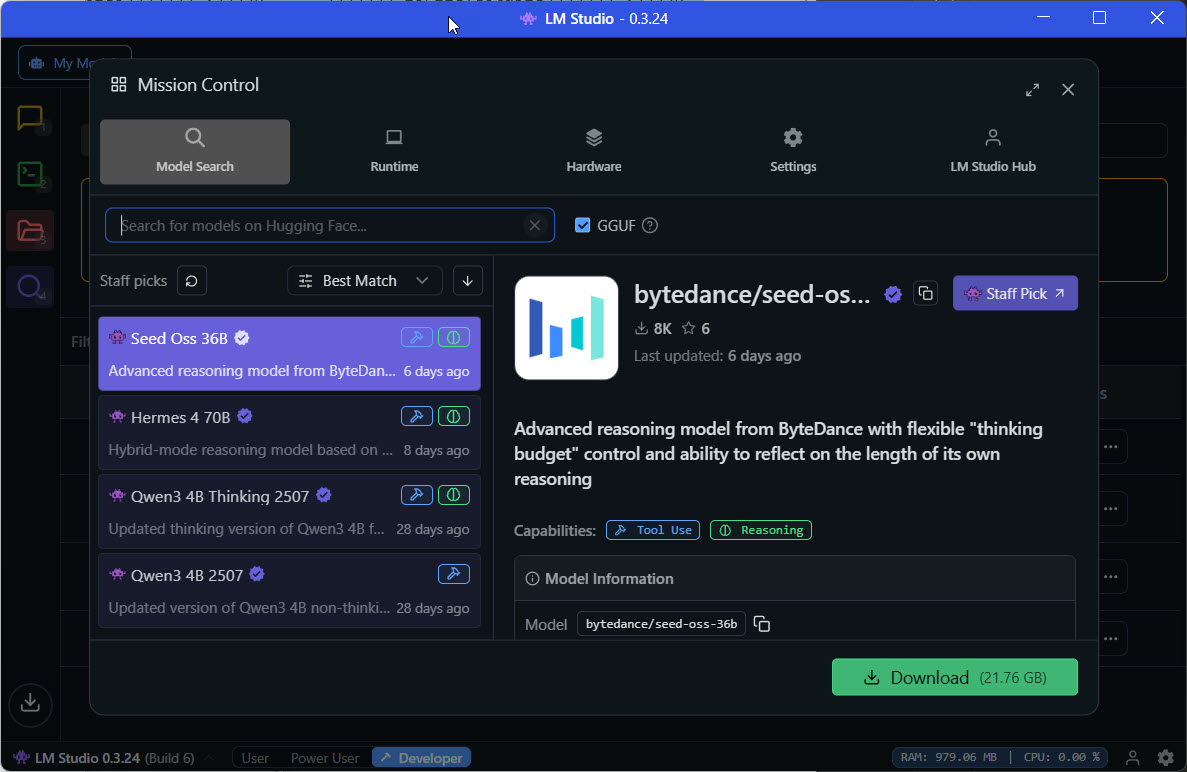
The Discover tab shows curated models optimised for local use
Choose a model that fits your hardware
For Houtini LM, we recommend these models based on your system specifications:
High Performance (16GB+ RAM)
- Qwen2.5-Coder-14B - Excellent for code analysis
- Llama 3.1 8B Instruct - Great all-rounder
- DeepSeek-Coder-V2-Lite - Specialized for development tasks
Balanced (8-16GB RAM)
- Llama 3.1 8B Instruct - Reliable performance
- Mistral 7B - Efficient and capable
- CodeLlama 7B - Good for code tasks
Download your chosen model
Click the download button next to your chosen model. The download will start automatically - models are typically 4-15GB, so this might take a few minutes depending on your internet connection.
Storage space heads up
AI models are large files - ensure you have at least 20GB of free disk space before downloading. Models are stored locally and can be deleted if you need to free up space later.
Step 3: Load the Model into Memory
Open the model loader
Once your model has finished downloading, press Ctrl+L (Windows/Linux) or Cmd+L (macOS) to open the model loader quickly. Alternatively, you can navigate to the Chat tab and click the model selection dropdown.

The model loader shows available models and memory usage
Select and load your model
Choose the model you downloaded and click "Load Model". LM Studio will allocate your computer's RAM to accommodate the model's weights and parameters. This process usually takes 30-60 seconds.
Memory allocation explained
Loading a model means moving it from storage into your computer's RAM so it can respond quickly to requests. You'll see a progress bar and memory usage indicator during this process.
Step 4: Monitor Houtini's Requests (Developer Tab)
Unlike typical LM Studio usage where you'd chat in the Chat tab, Houtini LM works differently. Here's what you need to know:
Switch to the Developer tab
Instead of using the Chat tab, click on the "Developer" tab in LM Studio. This is where you'll see Houtini LM's requests and responses in real-time.
Watch for "GENERATING" status
When Houtini LM is working, you'll see LM Studio show "GENERATING" in the Developer tab. This is how you know Houtini has successfully sent a prompt to your local model and is processing your request.
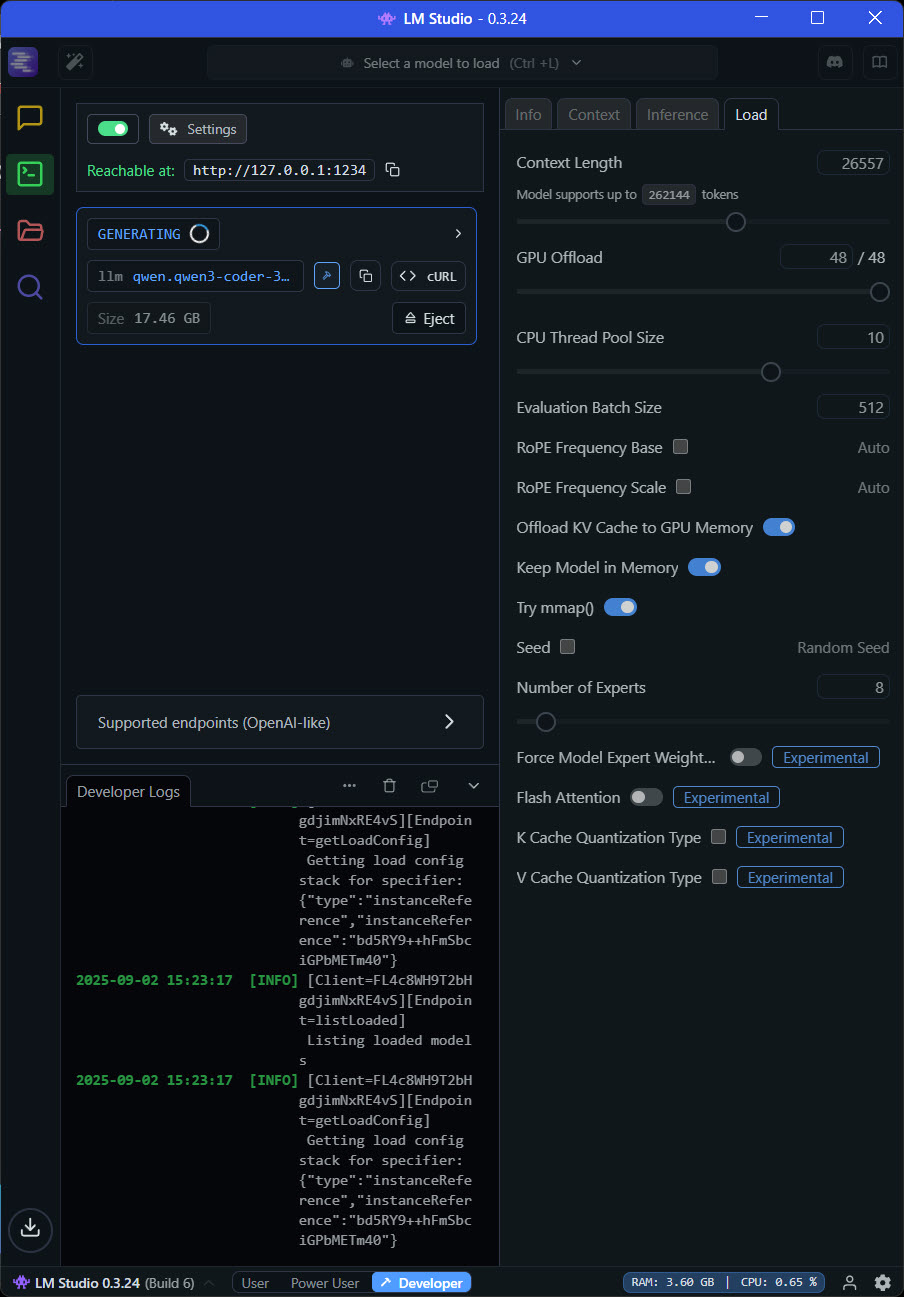
The "GENERATING" status confirms Houtini LM is successfully communicating with your local model
Understanding the workflow
Here's how it works: You send a command to Houtini LM through Claude Desktop → Houtini processes your request and sends it to LM Studio → Your local model generates the response → The results return to Claude for you to review and use.
Step 5: Optimize for Your Hardware
Getting the best performance from your local model can make a significant difference in speed and quality. Here are some optimization strategies:
GPU acceleration (if available)
If you have a dedicated graphics card with 4GB+ VRAM, LM Studio can use it to accelerate model processing significantly. This is automatically detected and configured in most cases.
Advanced optimization guide
For detailed hardware-specific optimization strategies, including CPU vs GPU usage, memory allocation, and performance tuning, we recommend this excellent community guide:
Advanced LLM Optimization Guide
Comprehensive video guide covering hardware optimization, model selection, and performance tuning strategies for various system configurations.
Model parameter tuning
In LM Studio's model settings, you can adjust parameters like context window size and temperature. For Houtini LM's analysis tasks, we recommend keeping the default settings initially and adjusting based on your specific needs.
Troubleshooting Common Issues
Model won't load - out of memory error
This happens when the model is too large for your available RAM.
- Try a smaller model (7B instead of 13B parameters)
- Close other applications to free up memory
- Consider a quantized version of the model (these use less memory)
- Check if you have enough free disk space for virtual memory
LM Studio not responding to Houtini requests
If Houtini can't connect to LM Studio, check these common issues:
- Ensure LM Studio is running and a model is loaded
- Check that LM Studio's server is running on the default port (ws://127.0.0.1:1234)
- Verify no firewall is blocking the connection
- Restart both LM Studio and your Claude Desktop application
Very slow response times
If your local model is responding slowly:
- Check if you're using CPU-only processing (GPU acceleration helps significantly)
- Try a smaller, more efficient model
- Close unnecessary applications to free up system resources
- Consider the optimization guide linked above for hardware-specific improvements
Download keeps failing
Model downloads can be interrupted by network issues:
- Check your internet connection is stable
- Ensure you have enough disk space (models are 4-15GB)
- Try downloading during off-peak hours
- Some antivirus software may interfere - temporarily disable if needed